히스토그램(Histogram) 그리기
히스토그램(Histogram) 그리기
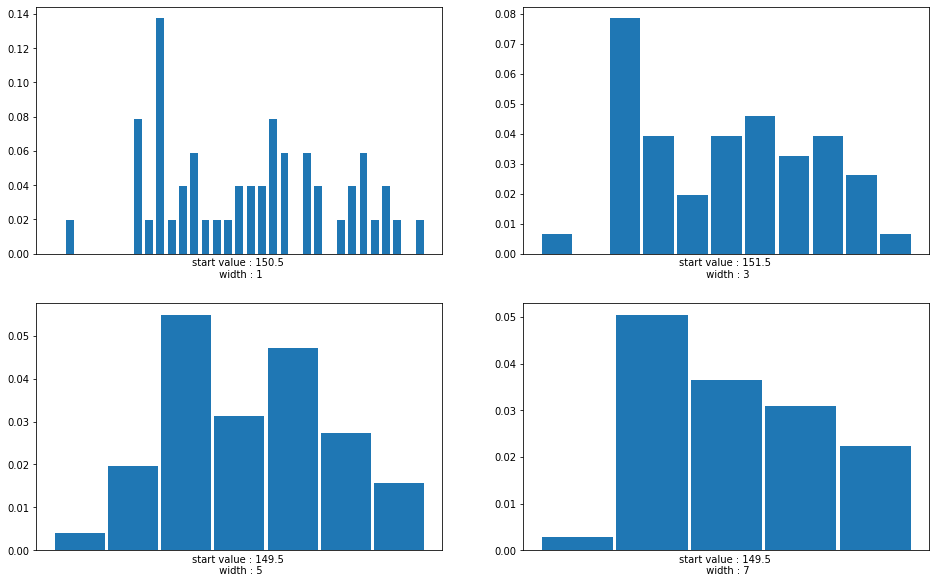
통계 관련 책(통계학 파이썬을 이용한 분석)을 보는데, 히스토그램을 시작값과 폭의 조건에 따라 분포의 형태가 다르게 나타나는 것을 보여주는 그림이 있어서 파이썬의 matplotlib를 이용해서 그려보았다. .
도수분포표를 기초로하여 각 계급에 대해 막대그래프와 같은 모양의 그림을 그릴 수 있는데 이를 히스토그램(Histogram)이라 한다.
보통 계급은 5~10을 사용한다고 한다.
시작값에 대한 부분도 분포의 형태에 영향을 준다고 한다.
히스토그램은 계급 구간의 폭을 동일하게 하거나 다르게 할 수 있는데, 계급구간의 폭을 다르게 하는 경우 상대도수를 계급 구간의 폭으로 나누어 계급구간 폭에 따른 영향이 없도록 해야 한다.
위에서 언급한 계급의 폭이나, 시작값에 대한 영향을 알아보기 위한 그래프를 아래의 코드를 이용하여 그렸다.
import numpy as np
import matplotlib.pyplot as plt
arr = np.array([181, 161, 170, 160, 158, 169, 162, 179, 183, 178, 171, 177, 163,
158, 160, 160, 158, 174, 160, 163, 167, 165, 163, 173, 178, 170,
167, 177, 176, 170, 152, 158, 160, 160, 159, 180, 169, 162, 178,
173, 173, 171, 171, 170, 160, 168, 168, 166, 164, 174, 180])
histo_cond = np.array([[150.5, 1],
[151.5, 3],
[149.5, 5],
[149.5, 7]])
fig, ax = plt.subplots(2, 2, figsize=(16, 10))
# 2행 2열의 그래프를 만든다.
for i, v in enumerate(histo_cond):
if i == 0:
i=0
j=0
x_axis_label = "start value : 150.5 \n width : 1"
elif i == 1:
i=0
j=1
x_axis_label = "start value : 151.5 \n width : 3"
elif i ==2:
i=1
j=0
x_axis_label = "start value : 149.5 \n width : 5"
else:
i=1
j=1
x_axis_label = "start value : 149.5 \n width : 7"
# 이건 어떻게 해야할지 몰라서 나오는 순서대로 i와 j를 입력하도록 했다.
histo_range, rel_freq = plot_histo_data(arr, v[0], v[1])
histo_range_means = (histo_range[:-1] + histo_range[1:])/2
ax[i][j].bar(histo_range_means, rel_freq/v[1], width=v[1]-0.3)
ax[i][j].set_xticks([])
ax[i][j].set_xlabel(x_axis_label, size=10)
def plot_histo_data(data, start_point, width):
# i : subplot index
# data : raw data (data type : numpy ndarray)
# histogram : start values
# width : histogram range width
no_class = (arr.max() - start_point)//width + 2
# 계급의 수를 정한다. 최대값에서 시작점을 빼고, 계급의 폭으로 나눈 후,
# 2를 더 한다. 2를 더하는 이유는 아래의 histogram 함수에서 마지막 값보다
# 아래의 값을 기준으로 결과를 반환한다.
histo_bins = np.arange(start_point, start_point + width*no_class, width)
freq, histo_range = np.histogram(data, histo_bins)
# histogram은 도수(freq)와 폭(histo_range)을 반환한다.
rel_freq = freq / len(data)
# 도수에서 전체 도수의 수를 나누어 상대 도수를 구한다.
return histo_range, rel_freq
위 코드를 사용하면서 배운 것은 아래와 같다.
-
subplots(2,2, figsize=(16,10)) : 2행 2열을 하게 되면 ax는 numpy 타입의 2행 2열의 배열이 된다. 따라서, 거기에 맞게 ax[0][0] 식으로 표기해 주어야 한다.
-
enumerate(histo_cond) : enumerate는 반복되는 객체의 인덱스와 값을 enumerate 객체로 반환한다.
그림을 2행 2열로 그리는 방법은 도저히 생각이 안 나서 그냥 if-else문을 사용했다.
전체적으로 여러가지로 부족하다.
그냥, 비슷하게 만든 것에 만족을 하자.
위 코드를 실행하면, 아래의 그림을 얻을 수 있다.
Written on June 22, 2021